


During the last 12 months, more or less, I had to build 3 different services that were highly concurrent and required some degree of resilience and fault tolerance. These services had different requirements and did completely different things, but after the third one, I noticed that I'm pretty much using the same recipe for the structure. That's what I'll talk about in this blog post, and at the end, I expect to have given enough insight into this recipe, so that you can also follow it in your next project or even make it better (if you have suggestions feel free to contact me at one of my socials).
Resilience & Fault Tolerance
In this title, I mention Resilience and there's also Fault Tolerance in the first paragraph. After all, what are these concepts about? I learned about them, more in-depth, back when I was getting my Master's Degree in Distributed Systems, and I've had them at the back of my mind every time I need to build a system that requires high availability and correctness.
If you want to be Fault Tolerant, then as the name says, it needs to be able to deal with possible failures that may occur. This ranges from writing defensive code, and being prepared to handle these errors, to the ability to maintain functionality when portions of a system break. The Wikipedia definition has the following analogy:
An example in another field is a motor vehicle designed so it will continue to be drivable if one of the tires is punctured, or a structure that is able to retain its integrity in the presence of damage due to causes such as fatigue, corrosion, manufacturing flaws, or impact.
The example above can also enter the realm of Resilience, but I see it more as the ability to recover from a partial or total crash. If you have a running service that shuts down for some reason, you may not need to do anything special when restarting, but for some occasions, it can be necessary to recover the previous known state and resume from that. These systems are very common when the previous state matters.
I think this Post from Uwe Friedrichsen makes a good summary of what Fault Tolerance is, and it also makes a comparison between both concepts, as they have a lot in common.
Please don't get confused or think I'm talking about Byzantine Fault Tolerance, as that's a matter for actual Distributed Systems, and not for Concurrent ones. Concurrency is also not the same thing as Parallelism, so what is Concurrency after all?
Concurrency
In computing, concurrency refers to multiple things that overlap in time, so that one starts before the other finishes, and they "fight" each other over CPU time. Parallelism is multiple things happening at the same time. Multiple processes or threads on a single time-sliced CPU might exhibit concurrency but not parallelism. Parallelism is about multiple tasks that literally run at the same time on hardware with multiple computing resources like a multi-core CPU. As per Rob Pike:
Concurrency is about dealing with lots of things at once. Parallelism is about doing lots of things at once.
In this blog post by Manning Free Content Center there's a great explanation including two images that inspired me to do my own below. You should definitely read it if you're interested in the matter. (Or if you just want the 5 year old explanation check Joe Armstrong's Concurrent and Parallel Programming.)
As for Distributed systems, well, they're distributed... Who would have guessed? 😅 This means that a distributed system is one in which components are decoupled from one another. Distribution also introduces issues of consistency and separate failure domains (that's where those Byzantine Faults enter). In a non-distributed system, consistency is often handled by that single machine and everything lives or dies together. If the hardware fully fails, then the service is completely down.
So here is a small summary just to consolidate knowledge before jumping on to the next phase of this post.
.")
.")
.")
The BEAM & Elixir
As almost everybody at this point knows, Elixir compiles into BEAM (the Erlang Virtual Machine) byte code (via Erlang Abstract Format). This means that Elixir code can be called from Erlang and vice versa, without the need to write any bindings.
For the ones that don't know Erlang or its background, it's a language developed back in the ‘80s by Ericsson for better development and stability of telephony applications, and that was made open source in 1998.
This way, Elixir has all of the benefits of the battle-proven system that is Erlang, and it is possible to use the existing Erlang libraries with no performance penalty. Another strong point for Elixir is concurrency (you probably see where I'm going with the line of thought), which, in most languages, is a bit of a pain. Not only is dangerous, but it's also hard to achieve synchronisation. In Elixir it is effortless to create a new process, and it performs very well. It is a core feature of the platform and does not require a separate library. Note that Erlang/Elixir processes are not native processes; they are much more lightweight and are scheduled by the BEAM.
So, introductions aside, from this point I'm going to assume that you have at least the basic knowledge about the Erlang and Elixir ecosystems.
If you're reading this, there's a chance that you already built some Phoenix Apps and know how amazing it is to build upon it while keeping the concepts above somewhat abstracted under it. However, that's not why I'm here today. Have you ever needed to build a resilient and concurrent system, just like Phoenix, for example, inside your usual Backend (if you're into Monoliths) or as a stand-alone app (if you're into Microservices)? In the case you already have, you may see a lot of similarities between them, and it's those that I want to talk about and include in my recipe.
Taking advantage of Supervisors
Erlang has the Let it crash philosophy, and that's where Resilience and Fault Tolerance enter the scene. Don't get confused, the idea behind is not to let it crash and burn, but to let it crash and recover. Instead of having uncontrolled failures, Erlang turns failures, exceptions and crashes into tools that we can use and control.
The language comes with a lot of different tools, and you should definitely learn more about them. Here, I'll mostly prioritise Supervisors, but in this Medium post you can find more info on Processes, Monitors, and others.
Even though Supervisors come from Erlang, I want to clarify that from now on I'm talking of Supervisors on Elixir. Looking at the definition in the Elixir docs:
A supervisor is a process which supervises other processes, which we refer to as child processes. Supervisors are used for building a hierarchical process structure called a supervision tree. Supervision trees provide fault tolerance and encapsulate how our applications start and shut down.
The Supervisor process has the job of looking at the health of its child processes and acting accordingly to the specified configuration and strategy. These can range from configuring:
:shutdown: defines how a child process should be terminated.:restart: defines when a terminated child process should be restarted.:strategy: how the supervisor should act when a process terminates.:max_restarts: the maximum number of restarts allowed in a time frame.
There are several more, and each of these has various options, but I feel that with the ones above you can already grasp what we can achieve with Elixir to quickly develop a Fault Tolerant and Resilient service.
Dynamic and Partition Supervisors
-
DynamicSupervisor: As the name implies, it's a supervisor that starts children dynamically. TheSupervisormodule (in Elixir) was designed to handle mostly static children that are started in the given order when the supervisor starts. ADynamicSupervisorstarts with no children. Instead, children are started on demand. When a dynamic supervisor terminates, all children are shut down at the same time, with no guarantee of order. We'll see them in my simple framework for these services. -
PartitionSupervisor: A supervisor that starts multiple partitions of the same child. Certain processes may become bottlenecks in large systems. If those processes can have their state trivially partitioned, in a way there is no dependency between them, then they can use thePartitionSupervisorto create multiple isolated and independent partitions. It's also possible to combine aPartitionSupervisorwith aDynamicSupervisor(check this amazing post by AppSignal for a concrete example).
A simple Framework
We have the concepts in place, and we also know about Erlang/Elixir tools to manage processes, so it's time to jump into some actual code.
The following image tries to represent the base structure I've been using for these last 3 services I had to build/incorporate into an Elixir app. It all starts by starting a DynamicSupervisor under the main App Supervisor (usually where the Application code is). Then this DynamicSupervisor starts and manages all worker processes that should do all the heavy and concurrent lifting. Note that as stated above, the DynamicSupervisor can be replaced or mixed in with a PartitionSupervisor if the use case requires (in my situation, I haven't had to use them yet, but they are next in line if there is any bottleneck in the process).
With this approach, you can also guarantee that an unhealthy Worker Process won't affect the others, as they are separate entities. If you want to ensure synchronization between them, then adding a new Manager process can be an easy solution (check my previous blog post on Simulations with Elixir for a quick example). For the hard way but more robust, you probably need to look into Consensus Algorithms, but that's more in the realm of Distributed and not Concurrent only systems.
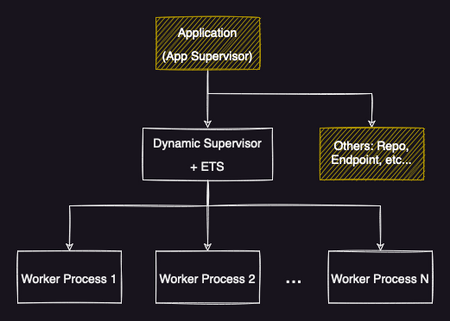
You probably noticed a new term in the image, theETS or Erlang Term Storage. An ETS allows us to store any Elixir term in an in-memory table and use it as a cache mechanism (learn more about them). I usually use this table to keep track of Worker Processes' PIDs and other metadata about each one of them (depending on the use case and the amount of information that each Worker needs to know about itself, or others). Be careful not to use it as a cache prematurely! It's an in-memory store only! For persistent solutions, we'll see other possibilities, below.
Usually, I also add some client functions to the DynamicSupervisor module, in order for Worker Processes to be able to update info on the ETS or trigger the start/stop of other Workers if needed. These functions can be abstracted into a separate Module if this one starts to grow indefinitely, and you feel they should be separated.
defmodule MyApp.MyModule do require Logger use DynamicSupervisor def start_link(init_arg) do with {:ok, pid} <- DynamicSupervisor.start_link(__MODULE__, init_arg, name: __MODULE__) do # Extra logic here if needed {:ok, pid} else _error -> Logger.error("Error starting MyApp") end end @impl true def init(_init_arg) do DynamicSupervisor.init(strategy: :one_for_one) end def start_worker_instance(args) do spec = {MyApp.MyModule.Worker, args} with {:error, error} <- DynamicSupervisor.start_child(__MODULE__, spec) do Logger.error("Error starting new Worker: #{inspect(error)}") end end def stop_worker_instance(some_id) do with {:ok, pid} <- get_pid_worker_instance(some_id) do Worker.stop(pid) {:ok, :closed} end end def get_pid_worker_instance(some_id) do case :ets.lookup(:my_ets_table, some_id) do [] -> {:error, :not_found} [{_some_id, pid, _rest}] -> {:ok, pid} end end def delete_worker_from_ets(some_id) do :ets.delete(:my_ets_table, some_id) end def insert_worker_in_ets(some_id, pid, rest) do :ets.insert(:my_ets_table, {some_id, pid, rest}) end # ... end
With the piece of code above, we already have a very basic supervision tree that can help us achieve a lot of things without much hassle. If a Worker Process dies, it's restarted, and the same thing for the DynamicSupervisor itself. Don't forget to start this Supervisor under the Application, or another already there.
The code for the Worker usually looks something like this:
defmodule MyApp.MyModule.Explorer do require Logger use GenServer, restart: :transient def start_link(args) do {:ok, pid} = GenServer.start_link(__MODULE__, args) MyApp.MyModule.insert_worker_in_ets(args.some_id, pid) send(pid, :start) Logger.info("Starting #{args.some_id}.") {:ok, pid} end def stop(some_id) do GenServer.stop(some_id) end @impl true def init(init_arg) do # new_state = some kind of computation on init_arg {:ok, new_state} end @impl true def handle_info(:start, state) do # start work end # ... end
Note the usage of use GenServer, restart: :transient. This piece of code tells the Supervisor to not restart this process if it stopped in a normal/controlled way. Only in a case of a crash, it will be automatically restarted. (You can then play around with other options.)
Going the Extra mile
I want to reiterate that the approach, or "recipe" as I called it previously, is as simple as you can get in order to start. There are obviously a lot of extra things you can add to make your system even more robust to faults. Here are some of them, that I've used in the past.
Using a :dets and other disk storage mechanisms
Imagine the situation that our service is indexing Events that happen in a separate place. If the service completely fails, when restarting we want to resume/continue indexing in the place where we left off before the downtime. This way we won't have any duplicated events, and won't miss others while down.
We can achieve this with the help of disk storage-based mechanisms, like using a :dets or the Database itself. A :dets is very similar to the :ets, but it's disk-based instead. It features a lot of helper functions that you can find in the docs, including ways to quickly turn it into an ETS, if we want.
IMPORTANT NOTICE: if you use services like Heroku or Fly.io, relying on this file approach may not work! Changes to the filesystem on one machine may not be propagated to others and are not persisted across deploys and/or restarts (depending on service specifics, they don't work the same way).
To avoid the problem above, you can rely on your dedicated Database or other services like Redis to keep track of it. The start_link code for the Supervisor would look like this now:
def start_link(init_arg) do with {:ok, pid} <- DynamicSupervisor.start_link(__MODULE__, init_arg, name: __MODULE__) do :dets.open_file(:my_dets, []) restore_previous_state() {:ok, pid} else _error -> Logger.error("Error starting Dora") end end defp restore_previous_state do if :ets.whereis(:some_pid) == :undefined do :ets.new(:my_ets, [:set, :public, :named_table]) end case :dets.match_object(:workers, {:_, :_, :_}) do [] -> MyApp.Workers.list_workers() |> Enum.each(&start_worker_instance(&1.some_id, &1.extra_info)) list when is_list(list) -> Enum.each(list, fn {some_id, extra_info} -> start_worker_instance(some_id, extra_info) end) _ -> Logger.error("Some unexpected error happened!") end end
Note that it's also required to add/remove workers' entries from these tracking systems when a new Worker Process is started/stopped with success.
You can check our Dora, the TipsetExplorer repo with this approach, as one of the projects we submitted for the FVM Space Warp Hackathon.
Process Pool
If your use case requires a lot of Worker Processes, and you don't want to flood the BEAM with new processes, you should definitely go with a Process Pool solution. You can easily exhaust your system resources if you do not limit the maximum number of concurrent processes that your program can spawn. The solution is to use a set of workers (processes) to limit the number of connections instead of creating a process for every individual action. For this, I would suggest two different approaches:
Poolboy: widely used lightweight, generic pooling library for Erlang that addresses this issue. This Elixir School guide is very helpful to get started quickly.- Custom solution: if
Poolboydoesn't fit well within your constraints, you can always build your custom solution. For a previous personal project, I took the opportunity to build my custom solution, not because I had special requirements, but because I wanted to try my own thing. You can find the code for this custom pool here. The file code I linked is a "special type" of Worker Process, under theDynamicSupervisorsupervision tree, but only keeps track of the pool and other Process management-related things.
Different Handlers that can be plugged and played
Suppose we continue our Indexing example, highlighted in the persistent-store mechanisms chapter, and we have different ways to listen/query for those events being emitted. We could have for example a queue/socket for passive listening, but the other service could also feature an HTTP API that we could poll.
This way if we want an even more fault tolerant and resilient service, we can make our Worker Processes use different Handlers to interact with the external system. So, in case we start listening to events via a socket/queue and the external service has a failure on that section, we can switch to automatically polling it through the HTTP API. This approach requires some overhead to manage which handlers are being used, and when to switch between them.
Further Reading
"Concurrent Data Processing in Elixir: Fast, Resilient Applications with OTP, GenStage, Flow, and Broadway", by Svilen Gospodinov, is a book that talks about the Concurrency part I talked about here, and more, explaining things in more detail. It goes into more specific situations, use cases you may have, and which tools to use, as I only followed a more generic approach.
Wrapping up
We've now reached the end of this post... It was probably a bit too technical, but I tried to explain all base concepts in a way that any developer, with different degrees of experience, could understand the problem and the proposed approaches. If you have any suggestions to add under the Extra mile section or even the base Framework, feel free to reach out!
As hinted in the previous sub-section, there are a lot more things to be explored and looked at according to your needs. I don't believe this is a hammer, and all my problems are nails, and you shouldn't believe it also! However, I think it should give a good place to start for personal/side projects.

And as always, thank you for taking the time to read this, and see you in the next one 👋