


On the last weekend of October, we (finiam) participated in ETHLisbon, an Ethereum-related hackathon, and our submitted project, Matusalem, resembled a pension fund scheme but only for Crypto Assets - I won't dwell here into much details of the project, as we'll probably have a dedicated blog post explaining it.
So, why am I talking about an Ethereum hackathon and Genetic Algorithms? Well, by the title of this post, you can probably guess why. For the last few weeks I had been reading Genetic Algorithms in Elixir by Sean Moriarity, and I was hooked on giving them a try in a use case outside the book. Fast forward to ETHLisbon, and our idea for the project, we found a place where Genetic Algorithms could be a nice path to explore, trying to figure out from a set of Crypto Assets which ones should make it into our pension fund portfolio, and I became responsible for it.
The base idea
Forgetting the details of how the whole thing would work, in this blog post, we'll focus only on the process of calculating the percentages of the funds we should allocate to each asset from a given list, using Genetic Algorithms.
Starting from the simplest use case, imagine we have 4 Assets to choose from and invest the money. Let's call them assets A, B, C, and D. Supposing the table below represents their expected returns and associated risk (1-7).
| Returns (%) | Risk Level | |
|---|---|---|
| A | 4% | 1 |
| B | 2% | 3 |
| C | 8% | 7 |
| D | 5% | 4 |
If we wanted to calculate the percentages we should invest in each asset, just by looking at the expected returns, it's clear that we should put all eggs in the basket C. However, things are just not that simple regarding investments, as we can understand that different assets have different risk levels. Normally, the higher the expected return, the higher the risk, but that's not always the case. So, our final goal, for this hackathon, was to optimize for a portfolio allocation that would maximize returns while bearing minimal risk. How can we do that? (At least in a mathematical way).
Sharpe Ratio
Here comes in Sharpe Ratio. We can evaluate the investment performance based on the risk-free return. The risk-free return is the return of an investment with zero risks for the investor (for example US Government Bonds, etc.).
A Higher Sharpe metric is always better than a lower one because a higher ratio indicates that the portfolio is making a better investment decision.
Since Genetic Algorithms are an optimization problem, and I'll explain further down how they work, we can use Sharpe Ratio as the metric we want to optimize. It takes into account expected returns and also associated risks. But how does it work, then?
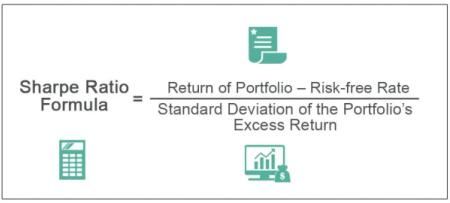
The image is from WallStreetMojo's explanation of the Sharpe Ratio, and I recommend reading it if you're curious about these subjects.
If you're not familiar with Sharpe Ratio or Statistics in general, you may be asking how does the formula above take into account the assets' risks? Well, that part is handled by the portfolio's standard deviation.
Portfolio Standard Deviation refers to the volatility of the portfolio, which is calculated based on three important factors that include the standard deviation of each of the assets present in the total Portfolio, the respective weight of that individual asset in the total portfolio, and the correlation between each pair of assets of the portfolio.
This way, if a portfolio has a high standard deviation it means that the risk is high, it has more volatility and therefore not so stable returns. A portfolio with a low standard deviation has less associated risk.
We will see below how we can calculate the standard deviation for a portfolio and use it inside our Genetic Algorithms' fitness function. But what is a fitness function?
Genetic Algorithms
As stated above, Genetic Algorithms are used to solve optimization problems. An optimization problem is a problem of finding the best solution from all feasible solutions. Usually, the solution to that problem is hard to obtain using conventional mathematics, requiring a lot of computation (brute force).
One example of an optimization problem is the Knapsack problem.
Genetic Algorithms help us overcome this brute force approach, by using certain heuristics that enable us to find a "good enough" solution, but not necessarily the best one.
Despite the cool name, how does a Genetic Algorithm actually work? It tries to mimic evolution the same way it happens in nature. Concepts like Natural Selection are known by almost everyone, and if you're reading this post, you're probably familiar with it. Individuals with certain variants of a trait tend to survive and reproduce more than individuals with other less successful variants. This gives that phenotype (with valuable traits) a reproductive advantage and may become more common in a population - survival of the fittest. A key part of this is also Sexual Selection, where this form of selection, together with Natural Selection, means that some individuals have greater reproductive success than others within a population, for example, because they are more attractive or prefer more attractive partners to produce offspring. A Genetic Algorithm takes these concepts and runs a sort of simulation for an evolution of a population.
In his book Genetic Algorithms in Elixir, Sean provides a simple scheme like the one below, that summarizes really well the different components that take part in these algorithms.

What does it mean, and how does it relate to Darwin's theories? Let's imagine we have a population for a species of Unicorns and follow the diagram above.
-
Initialize Population: In our case the starting population doesn't evolve out of a different species, it just gets "initialized randomly" (we'll see how we can represent a population later). That means that we start with a population of individuals we know are unicorns (four legs, a spiralling horn projecting from its forehead, etc), but their traits (genotypes) would be randomized across the entire population. Traits like height, horn size, muscle density, etc. A good starting population for these algorithms should be random enough (but still inside valid boundaries) so that we don't simulate evolution with a starting bias. The population size also needs to be a finite number, for example, 100 individuals.
-
Evaluate Population: In this phase, we give each individual in our population a rating, accordingly to a pre-defined fitness function. After the rating process, all individuals are sorted by the rating they got. The best one is checked against the termination criteria. What are the termination criteria? It's a function that verifies if we have reached an optimal solution (it compares with a reference value) or could check if the rating is getting better each generation, if we've reached a specific number of generations, etc. If this function determines to not stop the process, the algorithm advances to step 3, otherwise, it returns the best individual and its rating (fitness function) providing us with the solution for the problem.
-
Select Parents: If the simulation continues to this step, then we must select the parents for the next generation. Selecting parents is basically following the idea stated in the Sexual Selection theory, and we group the best individual with the 2nd best, the 3rd with 4th, etc. for all individuals in the population set. This way, we plan to create children out of the best chromosomes, with the hopes of obtaining a fitter individual out of the match.
-
Create Children: After grouping each individual it's time to generate their children. To create children out of each pair of parents, we'll use crossover. Crossover is analogous to reproduction. It’s a genetic operator that takes two or more parent chromosomes and produces two or more child chromosomes. So, supposing we have parents P1 and P2, we can combine them by splitting their chromosomes randomly, and obtaining four chromosome parts P1-1, P1-2, P2-1, P2-2. Children for these two individuals are the chromosomes P1-1|P2-2 and P1-2|P2-1. Repeating this crossover process for all parent pairs.
-
Mutate Children: Despite initializing the population to a seemingly random distribution, eventually the parents get too genetically similar to make any improvements during the crossover. In order to reach a proper solution, Genetic algorithms, also need to insert some entropy into the simulation, by provoking "mutations". Mutations to children's chromosomes should happen with a relatively low frequency, for example, a 5% probability of a mutation occurring. Mutations in Genetic Algorithms could range from shuffling individual genes', to swapping them entirely with a new value, etc. Too many mutations could add too much entropy to the algorithm, and it wouldn't get a proper result.
-
Start from step 2, and redo the process again, starting a new generation, until it reaches an optimal solution, triggered by the fitness function rating being high enough to reach the termination criteria.
I hope that this explanation has been enough to understand how a Genetic Algorithm works before we enter into the technical bits.
The Book's framework
When starting to read the book, after a more in-depth explanation of what I mentioned here (a lot of things in this post are from there, also), the author guides the reader through the development of a framework that we can use for almost any Genetic Algorithm problem with minimal adjustments to its base logic.
Recalling the simple flow specified above, we can see that some things can be abstracted through some code, by using a defined API for what chromosomes and genes should be. To fully grasp how we got to the next pieces of code, you'll need to read the book, but the most important parts can be summarized into the following:
- The definition of the
Chromosometype.- By using
:genesas anEnumwe can take advantage of all the existing functions. We can use complex structs to represent a singlegene, but the set of them follows the same API. - Defining other helpful fields like
fitness,sizeandagethat will help in the evaluation of the population.
- By using
defmodule Types.Chromosome do @type t :: %__MODULE__{ genes: Enum.t(), size: integer(), fitness: number(), age: integer() } @enforce_keys :genes defstruct [:genes, size: 0, fitness: 0, age: 0] end
- The
evolvefunction. This represents the flow above, where we get a population (list of Chromosomes), and iterate recursively overselection -> crossover -> mutation -> restartuntil the termination criteria are reached. I'll skip that part here, but this and the other functions remain almost the same across problems, but the book also shows different approaches.
def evolve(population, problem, generation, opts \\ []) do population = evaluate(population, &problem.fitness_function/1) best = hd(population) best_fitness = best.fitness IO.write("\rCurrent Best: #{best_fitness}") if problem.terminate?(population, generation) do best else generation = generation + 1 population |> select() |> crossover() |> mutation() |> evolve(problem, generation, opts) end end end
This way, the few things we need to worry about are providing the framework with an initial population and defining the terminate?(population, generation) function, which evaluates the termination criteria.
Using expected returns as Fitness Function
Recalling the problem stated above, for this project we wanted to know which Assets would make it into the portfolio using Genetic Algorithms. A good first approach for this, and one that is very simple, is just optimizing for the expected returns. Why? We can avoid the complex math related to Sharpe Ratio, and just worry about a singular variable: the asset expected return. We had already selected the assets we were going to use. Some of the expected returns, at the time of writing, were:
| ETH Staking | Uniswap | BTC | Maker | Filecoin | Aave |
|---|---|---|---|---|---|
| 4% | -0.0054% | -0.0017% | -0.0038% | -0.011% | -0.0009% |
Note that this return would be in ETH tokens, and not Euros or USD. Looking at the table, the crypto winter is clear, and the only positive return is ETH Staking (you can check more here on how it works). It's not necessary to be a great Math genius to understand that the best solution to optimize our risk-reward portfolio, a huge chunk (100% basically) of the allocation should be placed under ETH Staking, looking just at expected returns. It's the only positive one 😅. We can use this knowledge to scope out the values presented as results by our Genetic Algorithm. If the optimal solution, when the termination criteria are reached, has higher allocations on negative expected return Assets, then something is not right. Pretty easy, no?
Let's start by modelling our problem in a structure that corresponds to the framework's API.
- Gene: is a value ranging from 0 to 100, and represents the percentage of portfolio allocation to an asset. Initialized randomly.
- Chromossome: has a list of 10 Genes. One for each different asset we want to analyse. We made sure that the initialized sum of the 10 assets was under 100 (we can't allocate more than 100% of our portfolio).
- Population: 100 different Chromossomes. After each evolution round, we classify each Chromossome with the Fitness Function.
- Fitness Function: For this first approach, the fitness of a given Chromossome is just multiplying the algorithm-predicted allocation with the Expected Return for that respective asset, and summing everything at the end. That would give us the global expected return for our portfolio. Example:
@expected_returns [0.04, -0.000054, -0.000017, -0.000038, -0.00011] genes = [80, 5, 2, 3, 10] fitness = expected_returns |> Enum.zip(genes) |> Enum.map(fn {p, g} -> p * (g / 100) end) |> Enum.sum()
- Termination Criteria: When the population age reaches 10000. There were other possibilities for termination criteria, but you should definitely read the book to understand more about this.
Well, after running everything a couple of times the results were just random (yeah, I ran a couple of times just to make sure the results wouldn't be different). What was wrong with it, then?
- The culprit was the mutation function. I didn't talk about that in the previous paragraphs because I was relying on the function from the framework to run our algorithm. Big mistake. That function simply shuffled Genes around inside the same Chromossome, meaning that every time a mutation happened to a Chromossome in the evolution process, values from the initialization would just be shuffled, and not adding any entropy to the values themselves. That's why we always saw random values allocated for each Asset, it was just the random initialization.
- The solution for this required updating the mutation function. Instead of shuffling around the genes, the new mutation function should increase or decrease the current value randomly, so that values change throughout evolution. The code below solved that issue.
new_genes = Enum.map(chromosome.genes, fn gene -> range = floor(gene * 0.5) updated_value = gene + Enum.random(-range..range) if updated_value <= 0, do: 0, else: updated_value end) - However, problems didn't stop here. Now, we were having the best solution presented with
0at almost every gene, including the ETH Staking one, which is the go-to asset. This one was more difficult to find out the root cause because there were two different reasons.- Penalizing too much the very good Chromossomes. What's this about? Since that in the new mutation function, we're increasing the value randomly, sometimes the sum of all genes would be higher than 100 (something that we only account for in the initialization). Our fitness function had a small clause that if the sum of all genes was higher than 100, it would return
0for that Chromossome's fitness, because it would be an invalid individual. With this, we were penalizing too much the Chromossomes reaching close to 100% allocation, effectively killing all of them until only smaller values remain in the population. The solution was to remove that clause from the fitness function and normalise the values if the overall sum went over 100. - Penalizing too much the very bad Chromossomes. Looking at the mutation function there is the following line
if updated_value <= 0, do: 0, else: updated_value. The problem with this was that if a gene reached 0 or below (because of randomly decreasing the old value), the gene would never "recover" from that0value, effectively locking most of the assets' allocations to 0. Updating the line to something like:if updated_value <= 0, do: Enum.random(0..2), else: updated_valuefixed this problem, because it gives a small chance for that gene to have a different allocation value, and not just 0.
- Penalizing too much the very good Chromossomes. What's this about? Since that in the new mutation function, we're increasing the value randomly, sometimes the sum of all genes would be higher than 100 (something that we only account for in the initialization). Our fitness function had a small clause that if the sum of all genes was higher than 100, it would return
After these changes, we're getting pretty acceptable results where the Genetic Algorithm's best solution, presents ETH Staking with >90% allocations, and the other assets take home the rest 10%.
Using Sharpe Ratio as the Fitness Function
I've already explained what Sharpe Ratio is and why it's the final approach for this problem. TLDR, it also takes into account the inherent variation of Assets (associated risk) and not just their expected returns.
Recalling the Sharpe Ratio function from one of the images above, we need to know the portfolio expected returns, risk-free rate and the portfolio's standard deviation. We already know how to calculate the first two, we just need to calculate the standard deviation.
According to WallStreetMojo, the following formula is how you do it.

Where:
wX: allocated "weight" to assetX.R(kX, kY): the correlation between assetXandY.σX: Standard Deviation for assetX.
We pre-calculated all of the correlations between Assets, and the Standard Deviation for each one. Implemented the function to calculate the full portfolio's Standard Deviation, and replaced the fitness function above with the complete formula for Sharpe Ratio.
The results were just bad, and nonsense all over again... The problem this time was that the time until the end of the Hackathon was running out, and there were other things in the project that needed to be done, so after a couple of hours of debugging it, we decided to move over.
It's a bit of a bummer finishing things this way, but at this point, the issue was probably in the pre-calculated values and not in the Genetic Algorithm itself, as we just changed the fitness calculation. The main thing for this blog post is the algorithms, and not Hackathon rushed statistics...
Wrapping up
Looking back at how things went, I should have finished reading the book before the Hackathon 😅, to reduce some of the inherent stress that comes with participating in one, instead of going insane debugging why my population doesn't evolve properly.
Despite not reaching a perfect or even a "working" solution, I learned a lot about tweaking these algorithms (after all, evolution is not that simple). We also ended up winning a prize of 1500$ awarded by Protocol Labs for the third-best project of the hackathon using one of their products (Bacalhau - cod in Portuguese, which comes from the extended name of Computing over Data). We used Bacalhau to run our genetic algorithms simulation in a decentralized network of servers, that automatically stores its results in IPFS.

Have a look at the code written during the Hackathon in our Github repo (not just the Genetic Algorithms code), and feel free to reach out if you have any questions. A small disclaimer, remember that it is all Hackathon code, and it gets a bit messy...
Thanks for reading, and see you in the next one 👋